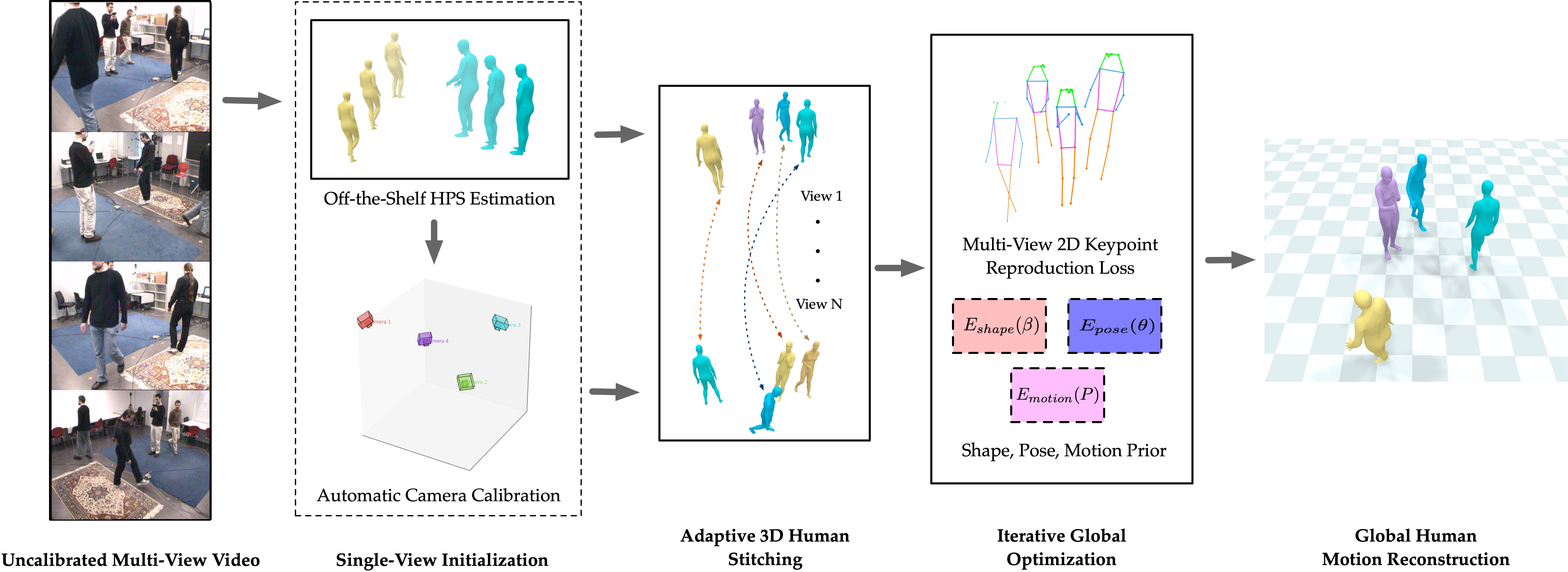
Easy3DReT: Uncalibrated Multi-view Multi-Human 3D Tracking & Reconstruction

Abstract
Current methods performing 3D human pose estimation from multi-view still bear several key limitations. First, most methods require manual intrinsic and extrinsic camera calibration, which is laborious and difficult in many settings. Second, more accurate models rely on further training on the same datasets they evaluate, severely limiting their generalizability in real-world settings. We address these limitations with Easy3DReT (Easy REconstruction and Tracking in 3D), which simultaneously reconstructs and tracks 3D humans in a global coordinate frame across all views with uncalibrated cameras and videos in the wild. Easy3DReT is a compositional framework that composes our proposed modules (Automatic Calibration module, Adaptive Stitching Module, and Optimization Module) and off-the-shelf, large pre-trained models at intermediate steps to avoid manual intrinsic and extrinsic calibration and task-specific training. Easy3DReT outperforms all existing multi-view 3D tracking or pose estimation methods in Panoptic, EgoHumans, Shelf, and Human3.6M datasets. Code and demos will be released.
Panoptic Dataset
Demo multi-view multi-human 3D tracking and reconstruction on the panoptic dataset, featuring 6 scenes with 1-6 human subjects in each. For each scene, we first present the original videos in 3-4 views, and demonstrate the corresponding 2D reprojections and 3D reconstructions.
Egohumans Dataset
Demo multi-view multi-human 3D tracking and reconstruction on the Egohumans dataset, featuring 4 scenes with 2-4 human subjects in each. For each scene, we first present the original videos in 2-4 views, and demonstrate the corresponding 2D reprojections and 3D reconstructions.
Further Qualitative Results
Below is a side-by-side qualitative evaluations of 3D pose tracking performance on the CMU Panoptic dataset. The superior consistency of our method is illus- trated in the top rows of each scene, where the individual encased in the red bounding box consistently retains their color designation, showcasing our method’s robust iden- tity tracking over time. In contrast, the bottom rows, representing the PHALP’ results, reveal the system’s vulnerability to occlusions, as highlighted by the individual in the orange bounding box receiving varied color identities, indicating identity switches.
All three rows of input videos below are from Panoptic. Three views are presented for each input video with a 3D reconstruction of human(s) on the right which is shared across all views. Below each input video row, we demonstrate the 2D reprojections of the 3D reconstruction for each view.

Below are additional Qualitative results of the proposed approach. All input videos are from the panoptic dataset. The columns compare results from three methods: PHALP’, SLAHMR, and EasyRet3D. The examples include different ranges of people (from N = 1 to N = 6) in a given scene. The examples include unusual poses, unusual viewpoints, people in close interaction, and severe occlusions. For each example we show the input image, the reconstruction overlay, a front view and a additional view. For our method EasyRet3D, we also show the reconstruction overlay to another view.
